PDF) Incorporating representation learning and multihead attention
Por um escritor misterioso
Descrição

Augmenting Self-attention with Persistent Memory – arXiv Vanity
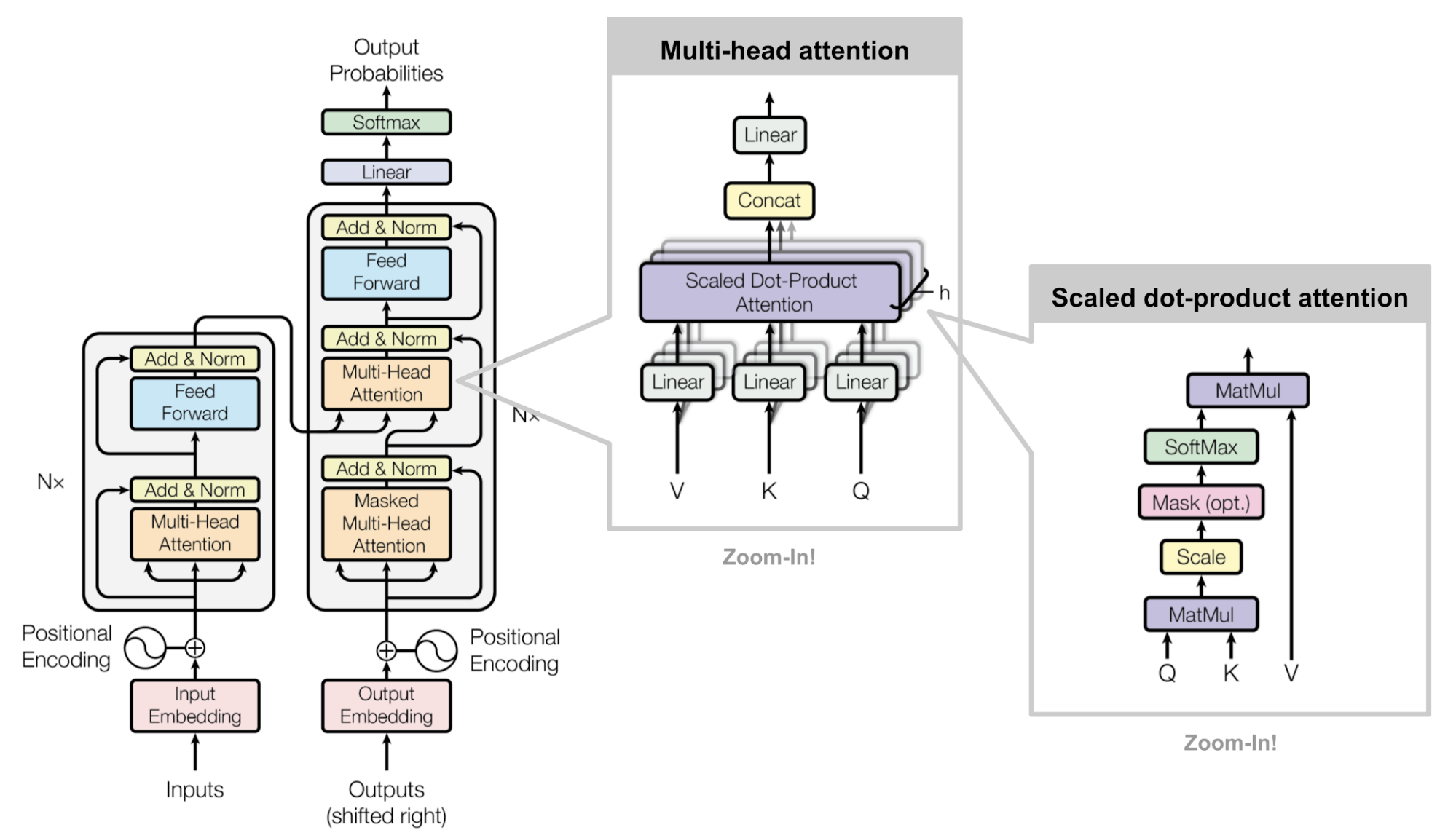
Attention

PDF] Tree Transformer: Integrating Tree Structures into Self-Attention
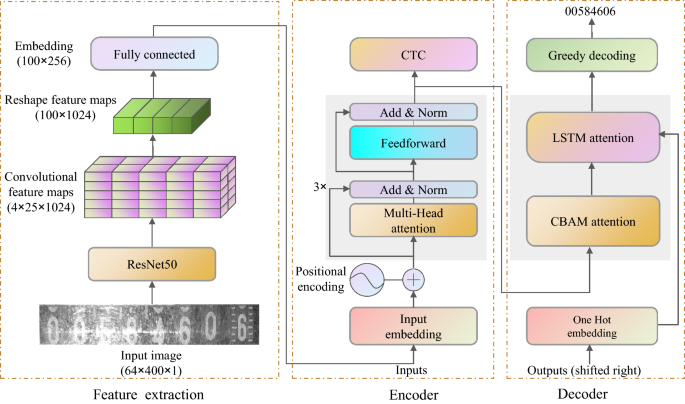
Multiple attention-based encoder–decoder networks for gas meter character recognition

GeoT: A Geometry-Aware Transformer for Reliable Molecular Property Prediction and Chemically Interpretable Representation Learning
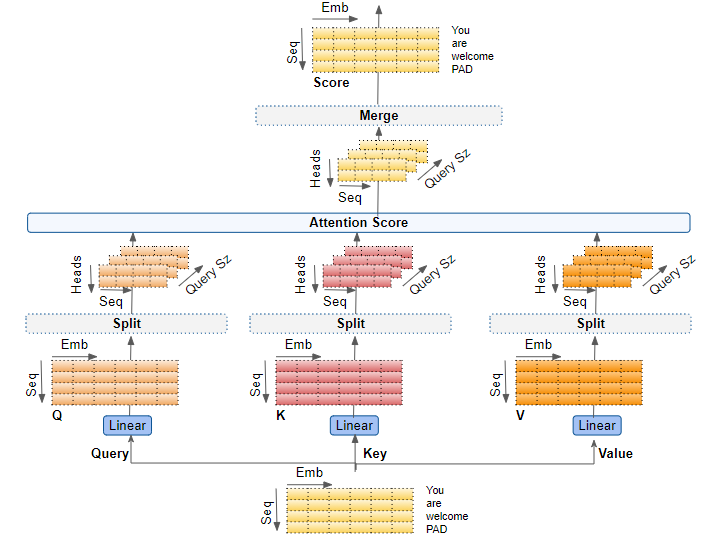
Transformers Explained Visually (Part 3): Multi-head Attention, deep dive, by Ketan Doshi
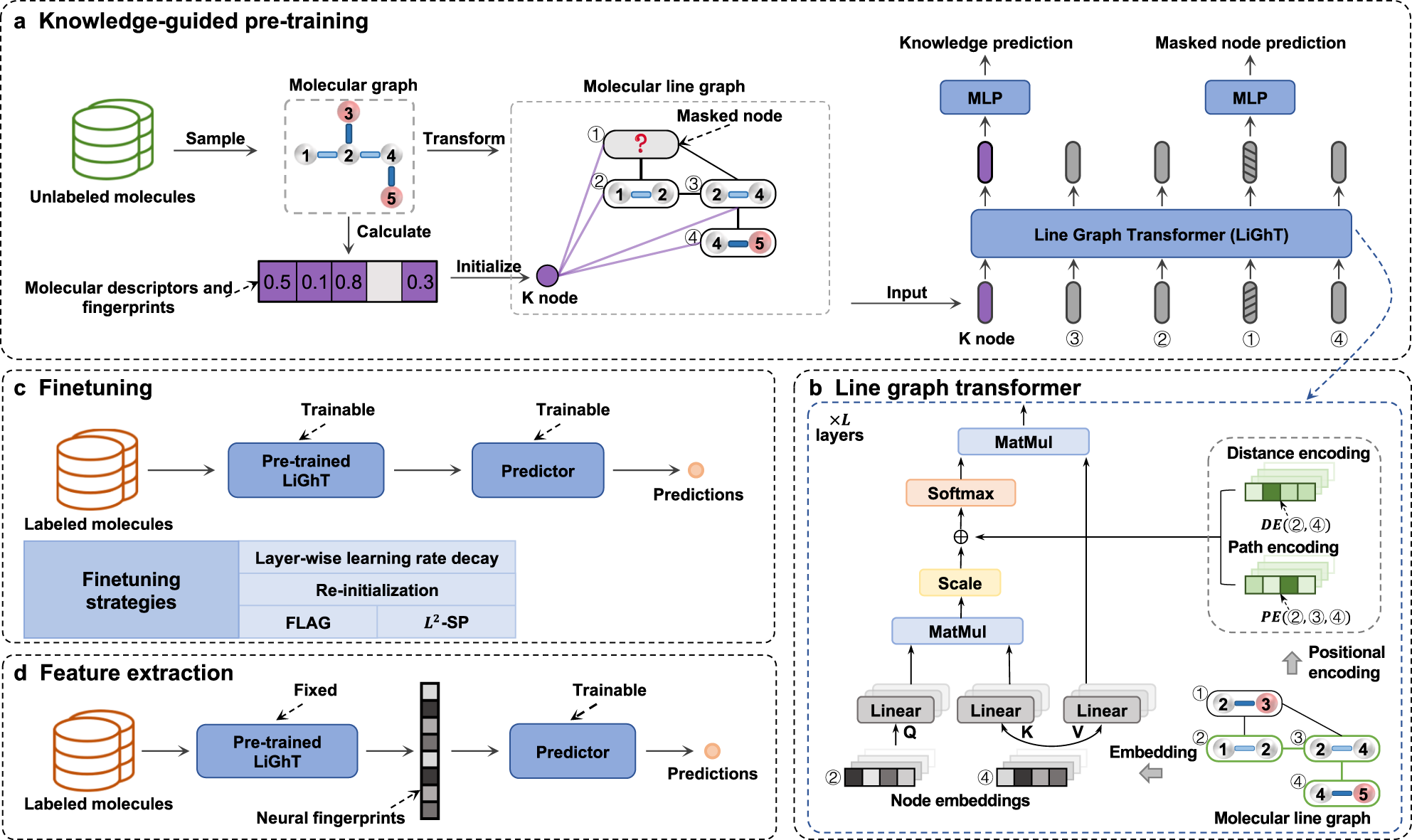
A knowledge-guided pre-training framework for improving molecular representation learning

RFAN: Relation-fused multi-head attention network for knowledge graph enhanced recommendation
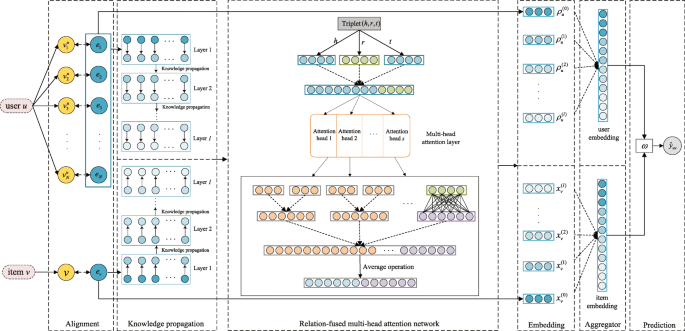
RFAN: Relation-fused multi-head attention network for knowledge graph enhanced recommendation
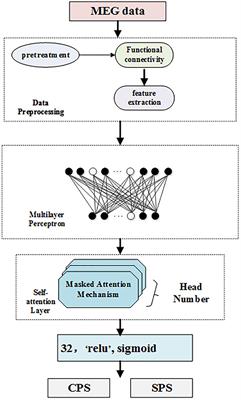
Frontiers Multi-Head Self-Attention Model for Classification of Temporal Lobe Epilepsy Subtypes

Multi-head or Single-head? An Empirical Comparison for Transformer Training – arXiv Vanity

Multi-head enhanced self-attention network for novelty detection - ScienceDirect

Multi-head enhanced self-attention network for novelty detection - ScienceDirect
de
por adulto (o preço varia de acordo com o tamanho do grupo)