AlphaGo Zero: Approaching Perfection, by Synced, SyncedReview
Por um escritor misterioso
Descrição
DeepMind recently published a paper in Nature introducing the latest evolution of its AI-powered Go program. “AlphaGo Zero” learns in self-play games, with no human knowledge required. The program…

DeepMind's AlphaGo Zero and AlphaZero

Is DeepMind's AlphaGo Zero Really A Scientific Breakthrough?

Data science Archives - Page 2 of 10
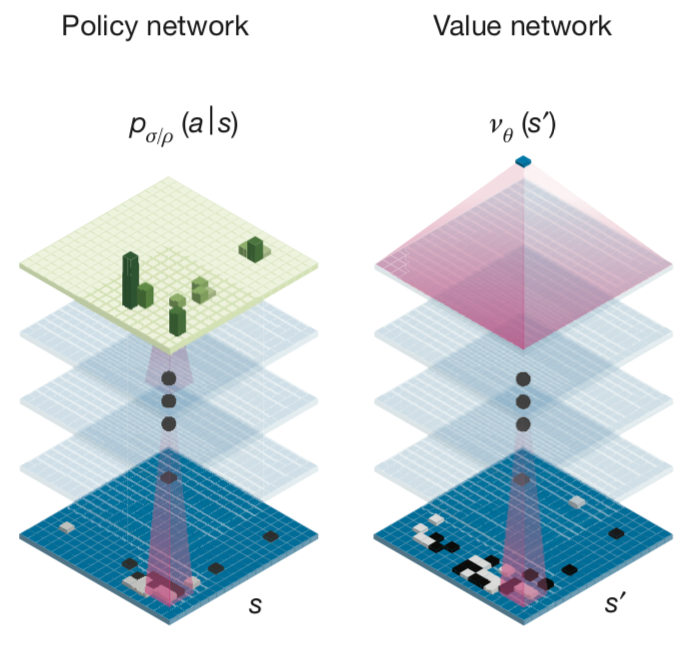
dThe 3 Tricks That Made AlphaGo Zero Work

AlphaGo

AlphaGo, in context. Update Oct 18, 2017: AlphaGo Zero was…, by Andrej Karpathy
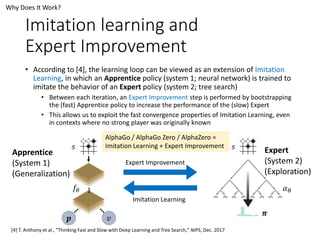
Introduction to Alphago Zero
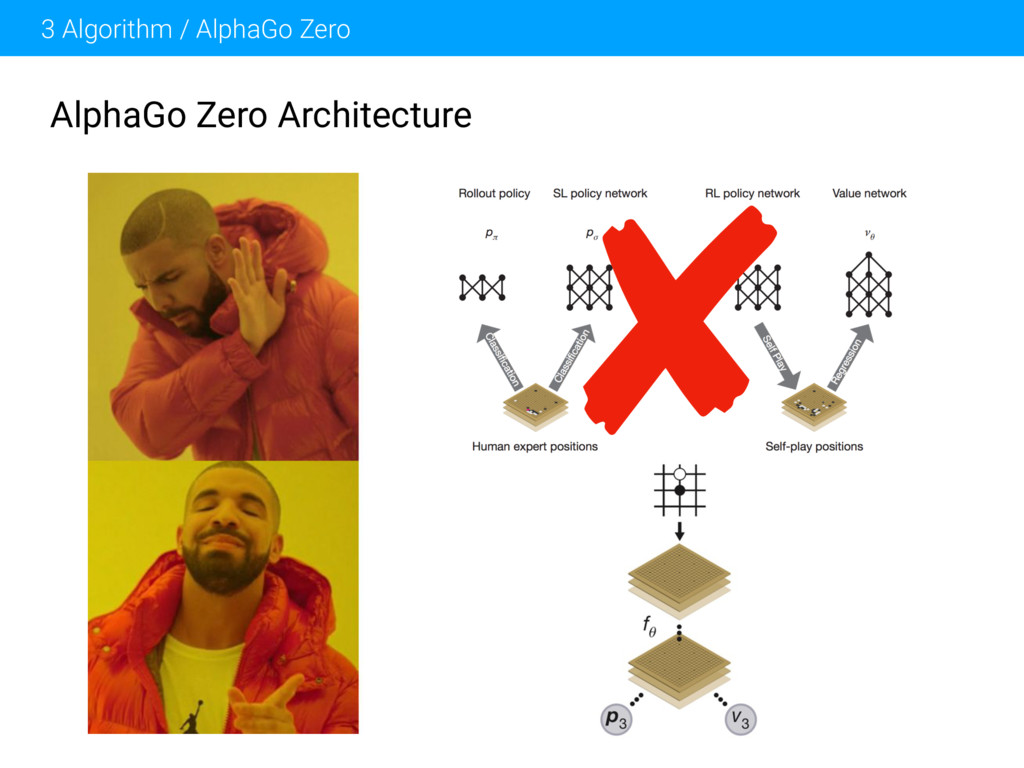
Algorithm behind AlphaGo and AlphaGo Zero - Speaker Deck
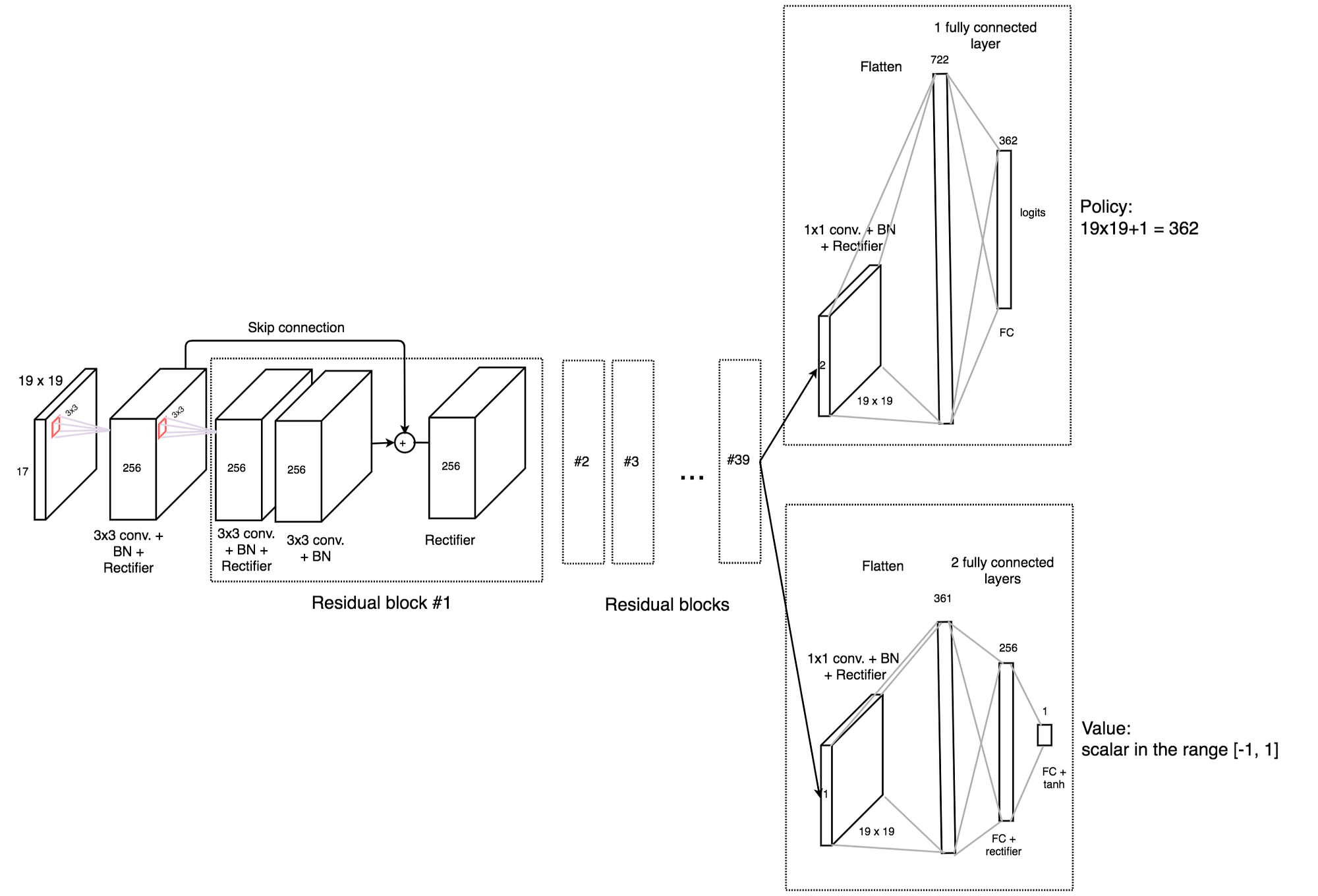
AlphaGo Zero — a game changer. (How it works?), by Jonathan Hui

Chapter 14. AlphaGo Zero: Integrating tree search with reinforcement learning - Deep Learning and the Game of Go
Data science Archives - Page 2 of 10

New Method Applies Monte Carlo Neural Fictitious Self-Play to Texas Hold'em
de
por adulto (o preço varia de acordo com o tamanho do grupo)